
Technology is a double-edged sword, and with data analysis comes an implied privacy breach, and I am working on developing tools to protect our privacy and digital assets.

As the data-driven digital economy flourishes, data security compliance has become a focal issue. With the application of cloud computing, big data, artificial intelligence and other new generation information technology, data, as a strategic and fundamental resource, is not only a link between virtual space and physical space, but also an important driving force for technological innovation, demand mining and efficiency improvement in the digital economy system. However, while data continues to create value, its security protection, compliance application and other issues have also become the focus of attention from all walks of life, including politics, industry, academia, research and application.
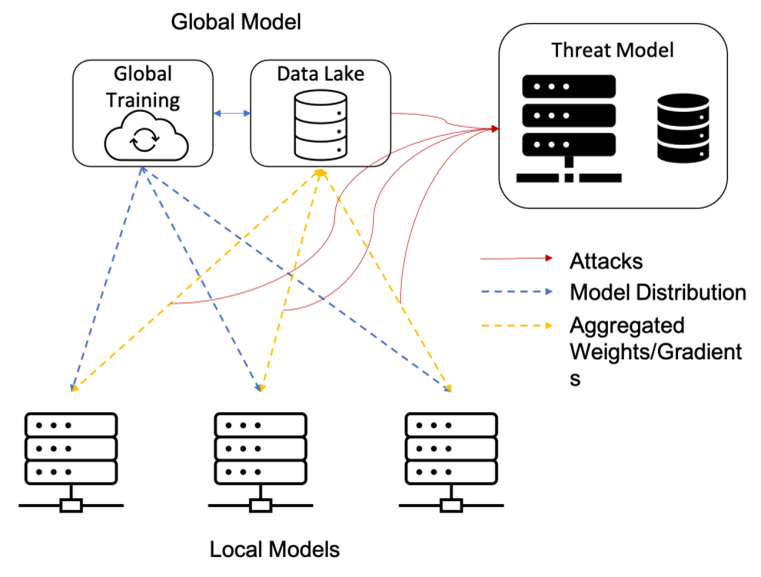
CLARIFY aims at developing a robust automated digital diagnostic environment based on AI and cloud computing. My research focuses on allowing secure analysis of sensitive health data. As we know, data is scattered across different hospitals and one needs more data to improve the performance of the models, which leads to issues of data privacy and security. In the healthcare industry there is a strong focus on protecting the privacy of medical data and there are even regulations that prohibit hospitals from sharing medical data. There are many different technical routes to privacy computing, such as federated learning, multi-party secure computing, trusted computing and blockchain. In the past I have looked at federated learning and blockchain technologies. Federated learning is a model of deep learning based on distributed training, which is characterised by the fact that instead of taking data, one shares models learned on local data and the models will be used as proxies for the data to train a better global model or to benefit each participant in the federated learning. A classic problem is that data from different institutions is non-iid (not independent and identically distributed), for example they are of different age or gender distributions. And we know that the distribution of data can directly affect the performance of the model. We have done some work to reduce the impact of non-IID so that the model can produce fairer predictions. As technology continues to evolve, blockchain has evolved from a tamper-proof, traceable, shared distributed ledger management technology to a distributed network data management technology that uses cryptography and distributed consensus protocols to ensure that data is maintained by multiple parties and cross-validated. While privacy computing achieves privacy protection for input data during multi-party collaborative computation, the original data, computation results and processes all face verifiability issues. The blockchain is used as a means of verifying key data and links in the computation process, ensuring the verifiability of the process. We have designed a blockchain-based decentralised identity system to support fine-grained access management of data in Federated Learning. This not only protects the privacy of users, but also protects the federated learning system from Sybil attacks(assume a attacker create lots of accounts and so something bad).
The picture illustrated the typical structure of federated learning with centralized aggregator, federated learning must take into algorithm effectiveness (non-IID) and system security(Sybil attacks).
Jiahui Geng – ESR3.