
A New Hotspot in Machine Learning Research: Privacy-Preserving Machine Learning

In my last blog, I introduced a potential threat of machine learning privacy disclosure: gradient matching attack, also known as gradient inversion attack I’m glad that the relevant work has been approved by International Workshop on Trustable, Verificable and Auditable Federated Learning in Conjuction with AAAI 2022.
In this article, I expanded the scope of the data reconstruction attack, showed that model sharing and gradient sharing algorithms (corresponding to FedAvg and FedSGD respectively) may lead to the leakage of training data, and proposed a more accurate one-shot label inference method.
Federated learning is an emerging distributed machine learning paradigm. The security analysis of machine learning can be analyzed from two perspectives. One is the CIA principle, that is, Credentiality, Integrity and Availability. CIA principle is an important analysis criterion for information system security. Credentiality refers to that training information cannot be accessed without permission. The user’s identity and user’s data in federal learning belong to this category. Integrity means that the system will not be tampered with maliciously in the process of training or inference. In fact, because federal learning gives each participant a lot of autonomy, the system cannot supervise the improper behavior of users. Availability refers to the fact that the system cannot work normally. Escape attack is the most typical case. The attacker generates countermeasure samples, which can invalidate the detection model.
The other is the adversary model angle. Attacker’s knowledge refers to the attacker’s understanding of model training. The white-box model means that the attacker knows all possible information. Black-box model means that users do not know the information of the model and can only observe the output of the model. The gray-box model is in between. In traditional machine learning, it is generally assumed that only one attacker has attacked at a certain stage. In distributed machine learning or multi-party cooperative machine learning, there may be multiple attackers in the system. Attacks may occur inside or outside the system. Of course, it is possible to attack both inside and outside the system. Active attack means that the attacker will actively affect the training or inference of the model, making the attack easier to occur. Passive attack, on the contrary, will not have any impact on the system.
Next, we analyze attacks in federated learning. Federal learning attacks mainly include security attacks and privacy attacks. Many people believe that security includes privacy, but here we separate privacy. Membership influence attack will judge whether a participant has joined the training of federal learning. Property inference attack will infer the properties irrelevant to the task unintentionally disclosed by the user. The data reconstruction attack will be the most terrible attack. The attacker (possibly the client or the server) will try to recover the user’s original data. Since federated learning will share information such as the structure of the model, half will not discuss model extraction attacks. Backdoor attack means that the attacker installs a backdoor in the model so that the model will act according to the attacker’s intention in the prediction stage. Robustness attack is an untargeted attack. The attacker just wants to break the training process of federal learning and make the final model unavailable. Escape attack refers to the counter attack in the machine learning system. The user generated counter samples escape the check of the target model.
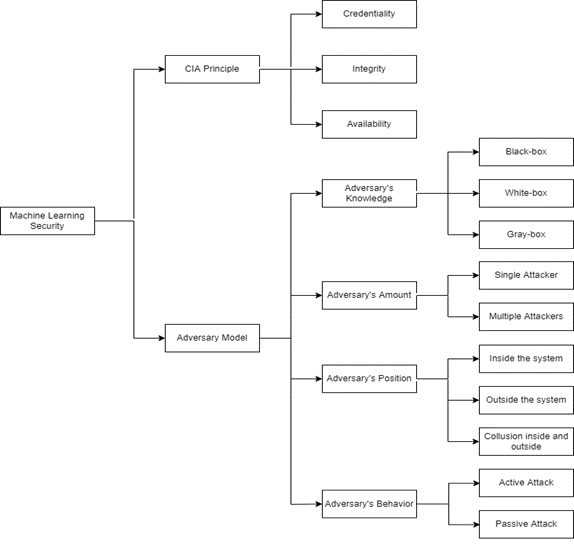
Figure 1. Machine Learning Security Analysis
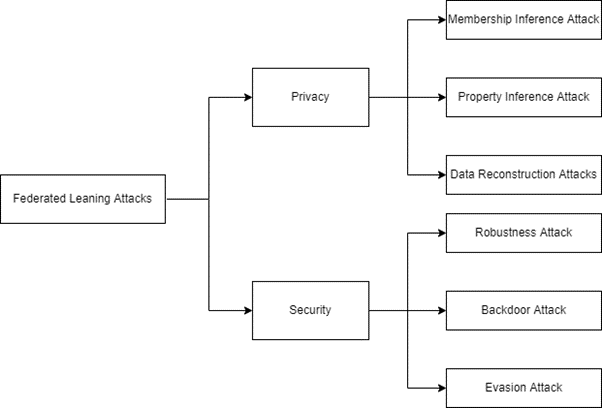
Figure 2: Federated Learning Attacks
Jiahui Geng – ESR3.