
Deep Learning (DL) is like Ballet dance. Ballet dance is beautiful but it has bad effects inside it for the dancer.

In this summer school, I had an opportunity to have several courses on different topics with the same aim! Machine Learning (ML). On the first day, I had a class with Prof. Danilo Vargas who talked about pixel attacks. Here, I would like to talk about it a little bit.
All we know that data comes slowly, but non-stop. To deal with this huge amount of information, computers and Artificial Intelligence (AI) can be effective. But when we look at AI it is just like a black box, because we can not see how it makes its decisions. In AI we feed the model with our input and we can receive the output (the results of classification, regression, recognition, etc.), without knowing the process in middle, Fig1. The point here is that if people cannot understand what is happening inside this black box, they won’t trust the systems. In Fig2. Michael Glitzner from Virtual Vehicle Research GmbH explains the risks and requirements. Nowadays, AI has been developed very well and there is a wide diversity of algorithms that can make a decision for humans, but here, it is important that people should trust them or the information should be safe. So, to spread the applications of AI, building this trust is on a data scientist to make machines more accurate and secure. Airlines do not build their own airport in every country; we should find general trustworthy algorithms for tackling problems.
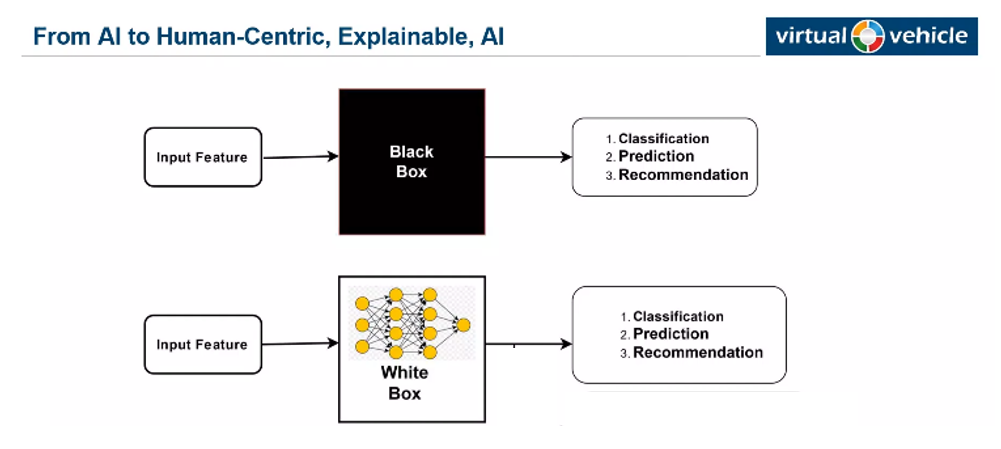
Fig1. Black box and white box in ML.
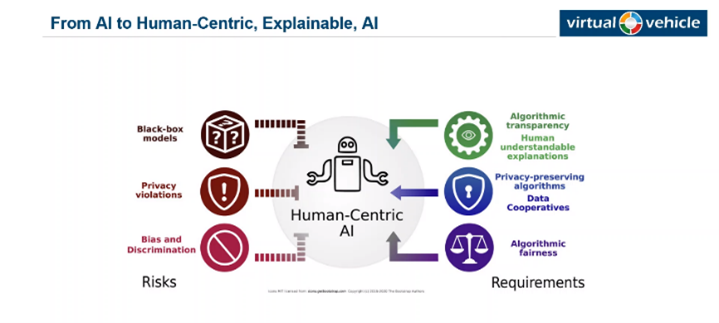
Fig2. risks and requirements in ML.
As ESR9 who works in the field of image processing, I have a responsibility to try my best to convert this black box to a white box. In Content-Based Image Retrieval (CBIR) we need to extract features and classify them. In there, we cannot see the features; we are just able to see the missing part of our image. By having more accurate features we can develop Deep Neural Network (DNN).
According to studies, if we feed the model by some images of a turtle at different angles, the classifier can classify it into different classes. A question here would raise, why do the classifiers classify the images of the same object into different classes? By doing different tests, it is found that by adding only one single pixel into an image, the classifier would have a different result, even if the image size is big. So, a simple change in an image can affect all layers, even the layers in deep. As a result, having one pixel more in the input can change the result in the output.
Deep Learning (DL) is like Ballet dance. Ballet dance is beautiful but it has bad effects inside it for the dancer, Fig3. Although it can work significantly, it might have some drawbacks and errors.

Fig3. Ballet dance is beautiful but it has bad effects inside it for the dancer
If we look at a light and try to increase and decrease the power of the light, the information can be increased or declined. This is the same in image processing, if we add a point into our input, the information in deep layers can be changed.
On the second day, I had a chance to attend a perfect class that Prof. Friedrich Fraundorfer explained some challenges in creating 3D images. By using 2 cameras in right and left of an object, 3D data can be available. But finding the same object point in both cameras can be challenging. Finding a small patch in a large image can be difficult by itself, but if the light has been changed it can be a critical problem. Imagine that we have noisy images, can you find similarities in them? Of course NOT! But computers can make patches and compare them to find similarities. In this condition, the computer would consider one pixel as a reference and it tries to find similar points in the other image. For one pixel in the reference image, we have several amounts that show the level of similarity between the reference pixel and other pixels in the same line of the matching image. To conclude, to find similar points between two images, first, they need a Feature Extractor (FE), then calculating similarity score, and finally calculating the cost.
Both of these classes in this summer school were talking about pixels to clarify that although one pixel is just one point, it can have tremendous effects on our results and accuracy. Also, all these concepts, analyses, and studies cross an important point in my mind!
BE CAREFUL WITH EACH SINGLE PIXEL IN WSIs.
Stay tuned!
Zahra Tabatabei – ESR9.

Summer school name: Beyond AI
Hosts: Dr. Matthias Scharrer, Prof. Daniel Watzenig, and Dr. Anton Fuchs
Organizers: Dr. Jelena Rubesa-Zrim, Dr. Alexander Thomas Goritschnig, and Prof. Horst Bischof.