
By proposing a network for CBIR we can make a platform for students, experts, professors, and … to be in touch and share their knowledge and their experiences.

Hi, world,
Do you remember my last post? Now, are you ready to start climbing together?
Let’s go.
In this post, I am going to share with you, what I found during these months. Maybe it would be interesting for all you pathologists and engineers.
In the last post, I mentioned a concept which is called CBIR. So, let’s talk about its concept at first.
What does CBIR mean?
Content-Based Image Retrieval (CBIR) consists of retrieving the most visually similar images to a given query image from a database of images.
Why do we need CBIR?
In general, the complexity of multimedia content is significantly increasing in the current digital world. This yields an exigent demand for developing highly effective retrieval systems to satisfy human needs. Recently, extensive research efforts have been presented and conducted in the field of CBIR.
But in our case, I would like to answer this question on the medical side, by explaining the process of diagnosis of cancers in a summary. Imagine that a clinician has a patient, he would do some tests on his patient then he would find that this person may suffer from cancer. So, he would grab a tissue from that considerable part, scan it to have its images, analyze it, consulting with other experts about it, and then he would make a decision to choose a proper drug. So, the point here is that before deciding for treating cancer, they need to consult. Imagine that we are going to prepare a network that can make this consultation easier and sprit it to the world. (See Figure1)
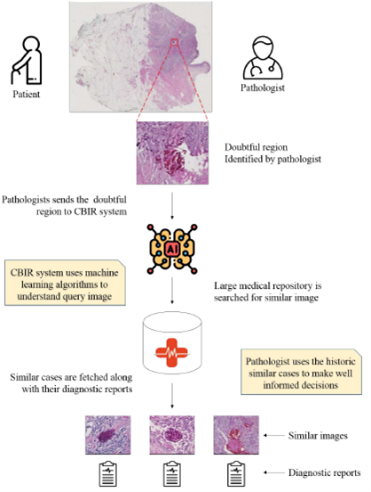
Figure 1. An overview of the project
By this explanation, two questions may come into mind. What kind of images would capture? How are we going to combine the concept of CBIR with this process? I am going to answer these questions, step by step.
What kind of images would capture?
There is a special type of histopathological image which is named Whole Slide Images (WSI). These gigapixel images can provide a huge amount of information for us although they need significant space to save them. So, to access their information and also to save the capacity of our system we asked some experts to find the region of interest (ROI) parts and split WSIs into small patches. As a result, our dataset is almost ready.
How are we going to combine the concept of CBIR with this process?
I am sure that with all these explanations you would find the answer to this question. But let me illustrate it a little deeper.
By proposing a network for CBIR we can make a platform for students, experts, professors, and … to be in touch and share their knowledge and their experiences. But now, we have a new question! How do we want to provide this network? What are its sub-steps?
Basically, we have two parts here, the dataset and the query image. Let’s review the sub-steps that are necessary to deal with these two parts.
- In the beginning, it is necessary to extract the features of our dataset. (We will use Auto-Encoders (AE))
- Secondly, we should make an inbox for the features that are extracted in the first step.
- In the next step, we would grab a new image as our query image and we should extract its feature with the same feature extractor as the previous steps. So, now we have a vector that represents the features of the query image and a box of vectors according to the dataset. I would like to name them query vector and inbox vectors, respectively.
- This is the time to find optimum distance metrics to calculate the distances between the query vector with inbox vectors.
- In the end, this is the time that we can select k-top similar images according to our query image by considering the distances. (The shorter, the better)
So, what are the challenges in these steps?
- Finding a proper feature extractor
- Choosing proper distance metrics
- Trian our model
- Preparing the dataset
- ….
Now it’s time for a conclusion.
By having this overview of almost the important sub-steps, keep track of our blog to reach more information and find out how we are going to pass these stages.
Zahra Tabatabei – ESR9.